Initiative for high-dimensional data-driven science based on sparse modeling
 Mankind's tireless curiosity of the natural world has led to never-ending improvements to our measurement techniques, resulting in the ongoing creation of large quantities of high-dimensional observation data every day. In this situation, to improve and consolidate the level of science and technology in an innovative way, it is essential to adopt an innovative naturalistic research methodology that achieves a close-knit interdisciplinarity between information science and the natural sciences. We believe that a key component of this methodology is sparse modeling technology, which has attracted a lot of attention in the field of information science in recent years. Sparse modeling is a generic term for techniques that exploit the inherent sparseness that is common to all high-dimensional data, enabling the efficient extraction of the maximum amount of information from data in real time, even in situations where there is an explosive exponential increase in computational load as the number of dimensions increases. So far, sparse modeling has achieved promising results in specific fields. If this technology can be strengthened by clarifying the common principles that apply in the background of each case, it will lead to innovative developments in all the natural sciences.
Mankind's tireless curiosity of the natural world has led to never-ending improvements to our measurement techniques, resulting in the ongoing creation of large quantities of high-dimensional observation data every day. In this situation, to improve and consolidate the level of science and technology in an innovative way, it is essential to adopt an innovative naturalistic research methodology that achieves a close-knit interdisciplinarity between information science and the natural sciences. We believe that a key component of this methodology is sparse modeling technology, which has attracted a lot of attention in the field of information science in recent years. Sparse modeling is a generic term for techniques that exploit the inherent sparseness that is common to all high-dimensional data, enabling the efficient extraction of the maximum amount of information from data in real time, even in situations where there is an explosive exponential increase in computational load as the number of dimensions increases. So far, sparse modeling has achieved promising results in specific fields. If this technology can be strengthened by clarifying the common principles that apply in the background of each case, it will lead to innovative developments in all the natural sciences.
Based on this recognition of the current situation, our aim in this program is to create a new scientific field, which we call "high-dimensional data-driven science", that can efficiently derive new scientific knowledge from large amounts of high-dimensional data through close collaboration between information scientists who are achieving remarkable results by sparse modeling and high-dimensional data analysis, and researchers who are using sparse modeling as a key technology for experiments and measurements in a wide range of natural sciences. In this way, by establishing an innovative scientific methodology based on a new set of common principles for the exploration of issues that have hitherto been separately explored in different fields, we will consolidate Japan's academic superiority in the coming age of data science by creating a large ripple effect in all fields of scientific research.
To realize this goal, we propose the following three key objectives.
- A:Practice of data-driven science: Making efficient use of high-dimensional data to solve individual problems in the natural sciences by bringing about a sea change in scientific methods.
- B:Establishment of modeling principles: Introducing a variety of different perspectives to develop a theoretical rationale of modeling methods for objects and phenomena based on similarities and common ground shared between different fields.
- C:Building a mathematical foundation: Narrowing in on mathematical issues from specific examples relating to non-linear and uncertain high-dimensional natural science data to revamp conventional multivariate analysis theory from an empirical perspective.
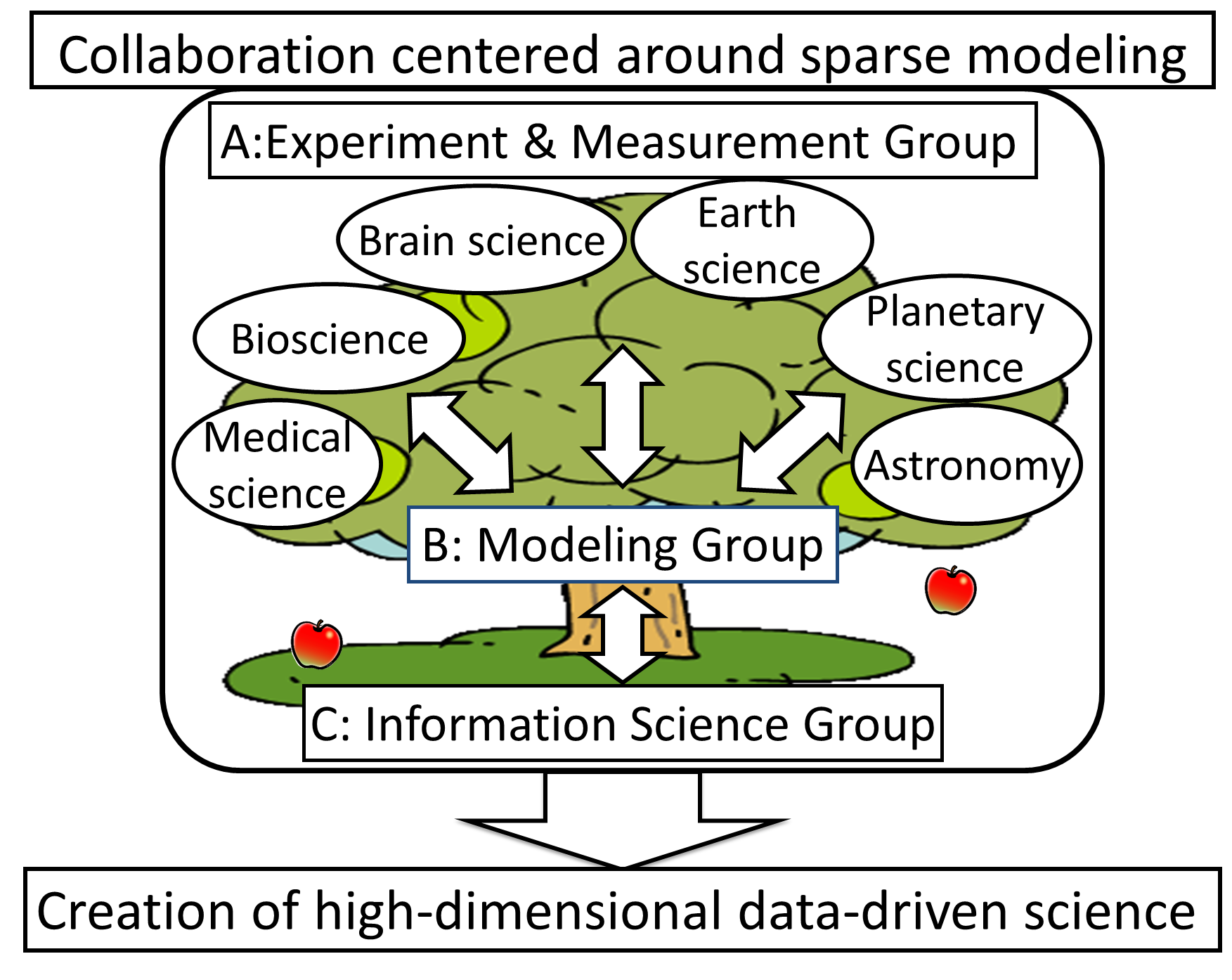
These objectives A, B and C are being examined by three groups: an (A01, A02), a (B01), and an (C01). In this project, which is aimed at achieving close collaboration and fusion between the natural sciences and information science, particular emphasis is placed on the role of the (B01) as an interface and catalyst. The (B01) is conducting research with interdisciplinary coordination studies as a central function in order to establish modeling principles that are as widely applicable as possible based on structural similarities.
Why sparse modeling?
Science is the action of discovering laws by (1) obtaining data by experiments and measurements based on a researcher's hypotheses and intentions, (2) selecting a small number of explanatory variables from this data, and (3) comparing these explanatory variables against the hypotheses. Today's science has developed through never-ending repetitions of this hypothesis proposal/verification loop. A classic example of this is the analysis of astronomical measurements whereby Kepler's laws evolved into Newtonian dynamics. On the other hand, in situations where data has become highly dimensional due to recent developments in measurement technology, resulting in an explosive increase in computational load, it becomes harder for researchers to follow their intuition in their contemplation of a subject or in trial-and-error experiments. This makes it very difficult to perform modeling based on a hypothesis proposal/verification loop. This sort of problem is particularly severe in scientific fields that are classed as "secondary science", such as biology and earth sciences, which are concerned with more complex phenomena caused by larger numbers of factors than in fields such as physics and chemistry.
Sparse modeling is a generic term for modeling that has been proposed to resolve such difficulties. Its basic idea is that of a framework in which (1) explanatory variables in high-dimensional data are assumed to be sparse (i.e., fewer than the number of dimensions), and (2) the number of explanatory variables is requested to be made as small as possible while at the same time requesting them to be consistent with the data, thereby facilitating (3) the automatic selection of explanatory variables without manual effort. The precursor of sparse modeling was a neural network model called "structural learning with forgetting", which was proposed in the late 1980s by Masumi Ishikawa (Kyushu Institute of Technology). In the mid 1990s, the arrival of methods such as the LASSO estimation method proposed by Tibshirani (Stanford University) and the automatic relevance determination (ARD) method of Tipping and Bishop (Microsoft Research) led to widespread recognition of the usefulness of this technique in the fields of bioinformatics and data mining. Furthermore, since the mid 2000s, a lot of attention has been drawn towards an innovative information extraction technique called compressed sensing (CS), proposed by Donoho (Stanford University) et al., which can be used in a wide range of fields such as measurement engineering, communications engineering, medical engineering and biochemistry.
What needs to be clarified, and how much?
 The (A01, A02) has made a breakthrough by establishing scientific methods that substantially increase the speed of experimental protocols and the discovery of new laws by making effective use of large amounts of high-dimensional data, centered on secondary science fields such as life sciences and geosciences where modeling from first principles can be difficult. To give an example, the A02-3 team (: Honma) has used sparse modeling of radio interferometry data to obtain images with 3-4 times the resolution determined by the diffraction limit, which is a major milestone in the fields of astronomy and astrophysics where efforts are being made to obtain direct observations of black holes (Science, Online September 27 2012).
The (A01, A02) has made a breakthrough by establishing scientific methods that substantially increase the speed of experimental protocols and the discovery of new laws by making effective use of large amounts of high-dimensional data, centered on secondary science fields such as life sciences and geosciences where modeling from first principles can be difficult. To give an example, the A02-3 team (: Honma) has used sparse modeling of radio interferometry data to obtain images with 3-4 times the resolution determined by the diffraction limit, which is a major milestone in the fields of astronomy and astrophysics where efforts are being made to obtain direct observations of black holes (Science, Online September 27 2012).
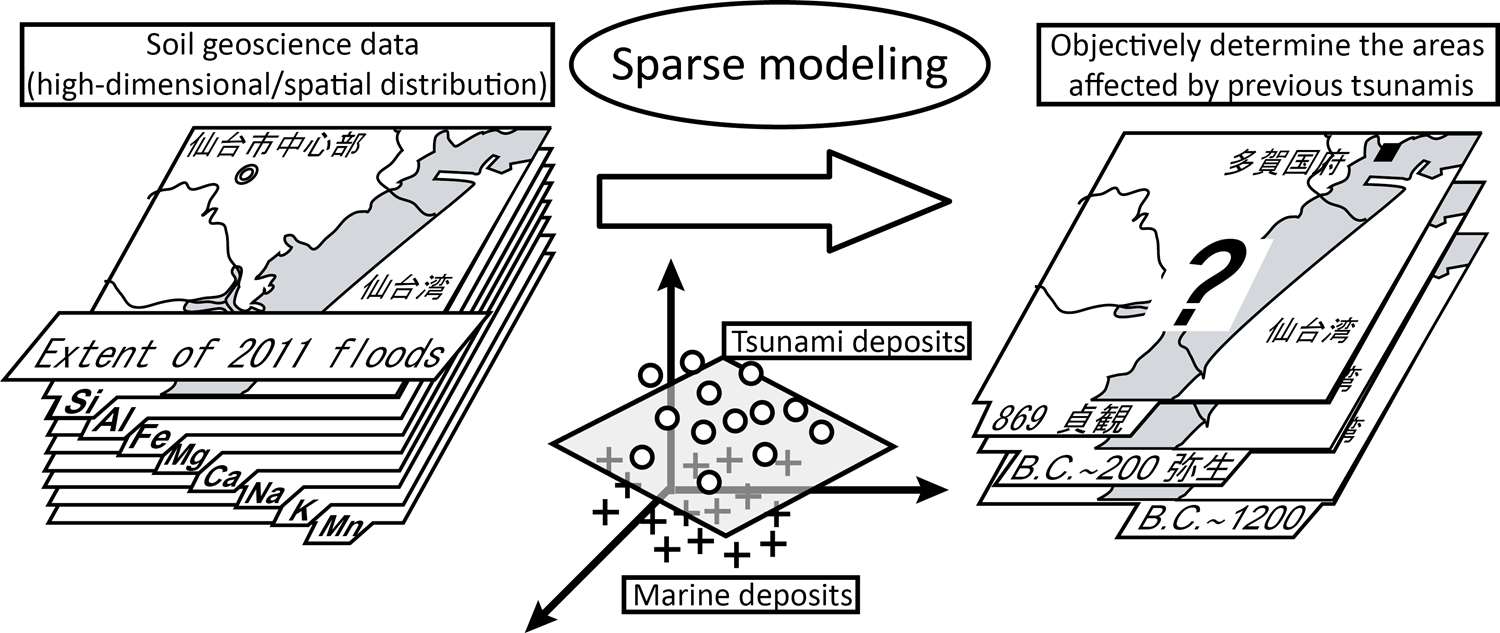 Also, in the field of medical science, the aim is to revolutionize MRI scanning techniques by reducing the scanning time by more than half, thereby making the procedure much easier on patients. In the bioscience, the aim is to reduce the time required for NMR scans from a few days to a few hours, which would cause substantial changes in the research to estimate the three-dimensional structure of proteins. In the field of brain science, the aim is to bring about a revolution in brain science and information science by clarifying the pattern recognition mechanisms in the temporal lobes. In the earth science, the aim is to predict the areas affected by tsunamis in the high-risk Tohoku region by extracting a small number of elements characteristic of tsunami deposits from high-dimensional earth science data.
Also, in the field of medical science, the aim is to revolutionize MRI scanning techniques by reducing the scanning time by more than half, thereby making the procedure much easier on patients. In the bioscience, the aim is to reduce the time required for NMR scans from a few days to a few hours, which would cause substantial changes in the research to estimate the three-dimensional structure of proteins. In the field of brain science, the aim is to bring about a revolution in brain science and information science by clarifying the pattern recognition mechanisms in the temporal lobes. In the earth science, the aim is to predict the areas affected by tsunamis in the high-risk Tohoku region by extracting a small number of elements characteristic of tsunami deposits from high-dimensional earth science data.
In the (B01), by studying the methodologies of system science to form connections between individual items of natural science data and the general-purpose analysis techniques of information science based on the similarities between mathematical structures across the field, we propose a general framework for systematic modeling based on a hypothesis and test cycle. In this way, we will establish a data-driven general phenomenology approach that solves individual problems by making use of analogies and generalizations across interdisciplinary boundaries.
In the (C01), we will establish a mathematical basis for sparse modeling by developing classical models that incorporate the features of actual situations, and renovating conventional multivariate analysis methods that have been strongly reliant on Gaussian characteristics. This is why we have set up s relating to three technologies needed for the analysis of natural science data: handling of nonlinear and hierarchical properties (, C01-1), modeling of states that are difficult to model with conventional frameworks (, C01-2), and breaking down the computational difficulties of high-dimensional data (, C01-3). We will also develop methods for providing experimenters with feedback that makes the analysis results easier to understand so as to enable the hypothesis and test cycle to work efficiently (, C01-4). Also, close collaboration between the (B01) and the (A01, A02) will facilitate optimal modeling of their respective systems based on the hypothesis and test cycle, which is the essence of the scientific method, and by eliminating them from data analysis centered on post-processing, we will extract the greatest possible scientific knowledge from natural science data.